
Music Emotion Volatility Prediction
A Feature-Based Analysis
Status: Research Completed
This research investigates whether the emotional volatility of music—how much listeners' emotional responses vary—can be predicted from acoustic features, and whether this prediction differs from predicting average emotional responses.
While most music emotion recognition focuses on mean responses, this study explores the often-overlooked dimension of emotional variance, revealing which songs evoke consistent emotions versus those producing highly varied listener experiences.
Presentation Video
Watch the complete research presentation explaining methodology, findings, and implications.

Research Hypothesis
H1 — Emotional Volatility is Predictable
Acoustic structure predicts variance of emotion better than, or at least comparably to, mean emotion.
Dataset & Approach
The study utilized the PMEmo (Personalized Music Emotion Dataset), which contains:
- Perceptual acoustic features
- Listener ratings across multiple contexts
- Emotion labels (Arousal and Valence dimensions)
This dataset enabled cross-listener context sensitivity analysis, making it ideal for examining emotional variance across diverse listening experiences.
Methodology Pipeline
Stage 1: Unsupervised Feature Pruning
Variance Filtering: Removed 279 near-constant features with variance below 1e-6
Collinearity Reduction: Eliminated 2,254 redundant features with correlation exceeding 0.95
Result: Feature space reduced from 6,373 to 3,840 features
Stage 2: Mutual Information Ranking
Applied Pareto selection, retaining features accounting for top 20% of total mutual information per target:
- mean_A: 135 features selected
- mean_V: 172 features selected
- std_A: 184 features selected
- std_V: 144 features selected
⚠️ Critical Finding: Zero intersection among all four targets — predicting mean versus variance requires fundamentally different acoustic information.
Model Training
- Algorithm: ElasticNet Regression
- Data Split: 70% Train / 20% Validation / 10% Test
- Preprocessing: Standardization after split to prevent data leakage
- Hyperparameter Optimization: Alpha and L1 ratio tuned via validation performance
Results: Static Feature Dataset
| Target | Train R² | Validation R² | Test R² | Interpretation |
|---|---|---|---|---|
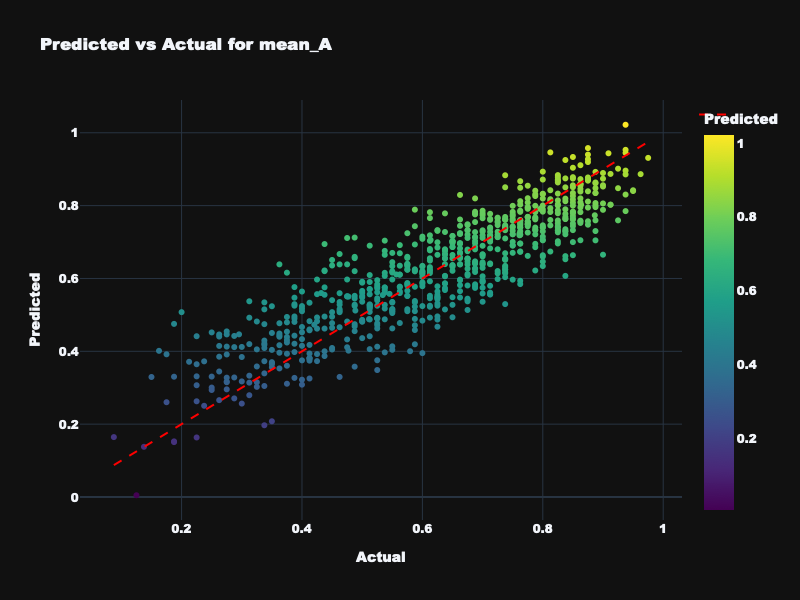
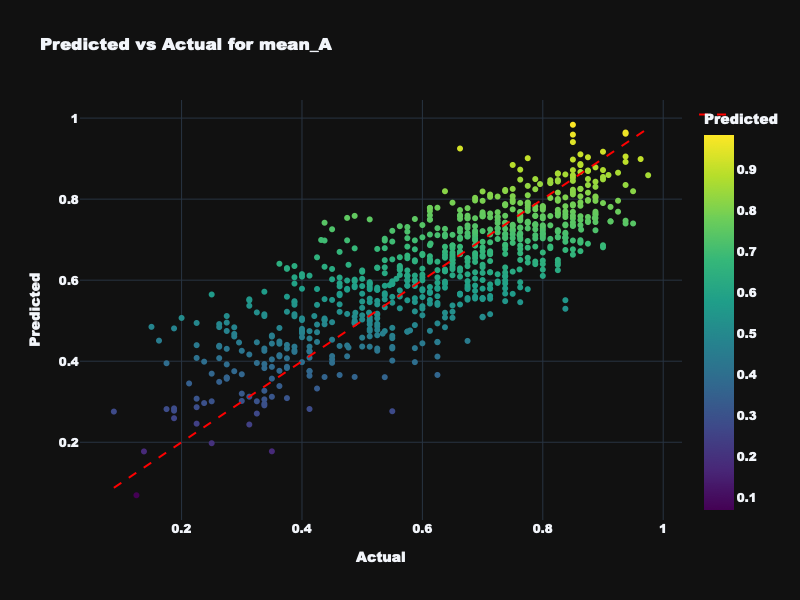
| mean_A | 0.797 | 0.780 | 0.707 | Excellent — mean arousal is highly predictable |
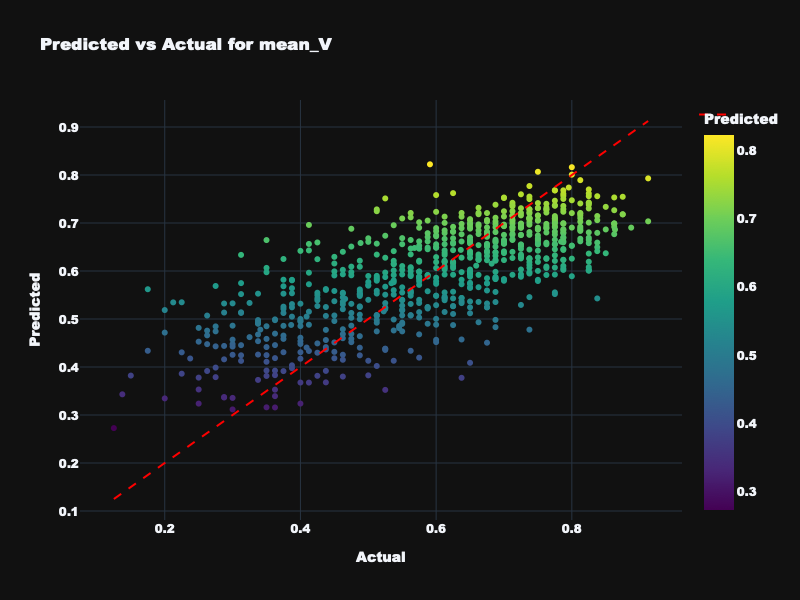
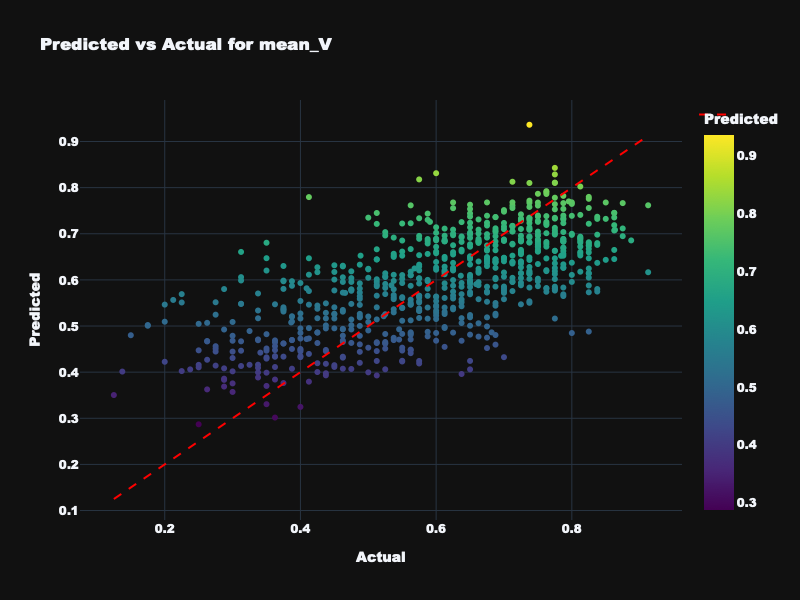
| mean_V | 0.551 | 0.562 | 0.493 | Moderate — mean valence is predictable but weaker |
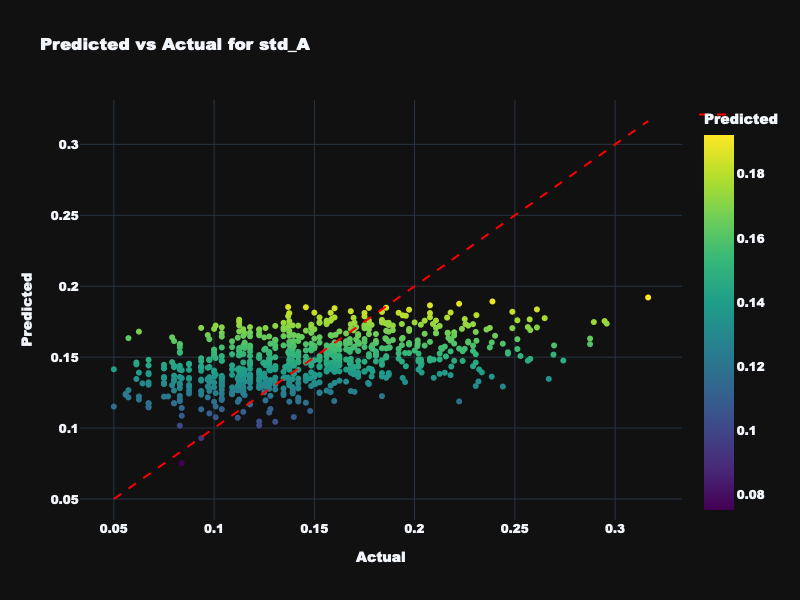
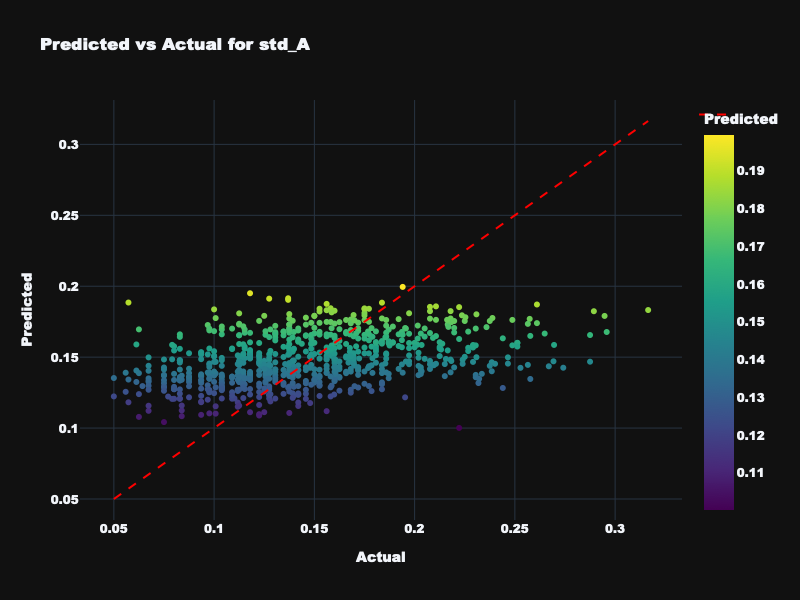
| std_A | 0.234 | 0.039 | 0.220 | Low — arousal variance is difficult to predict |
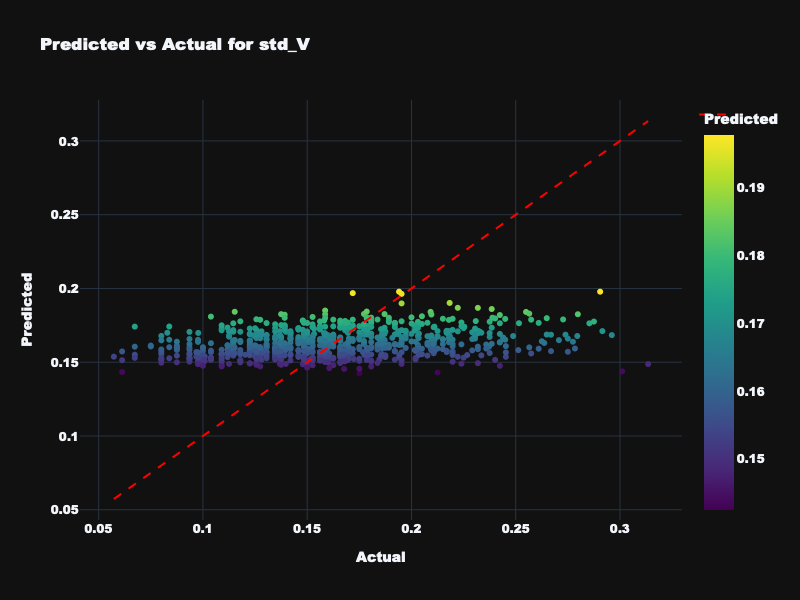
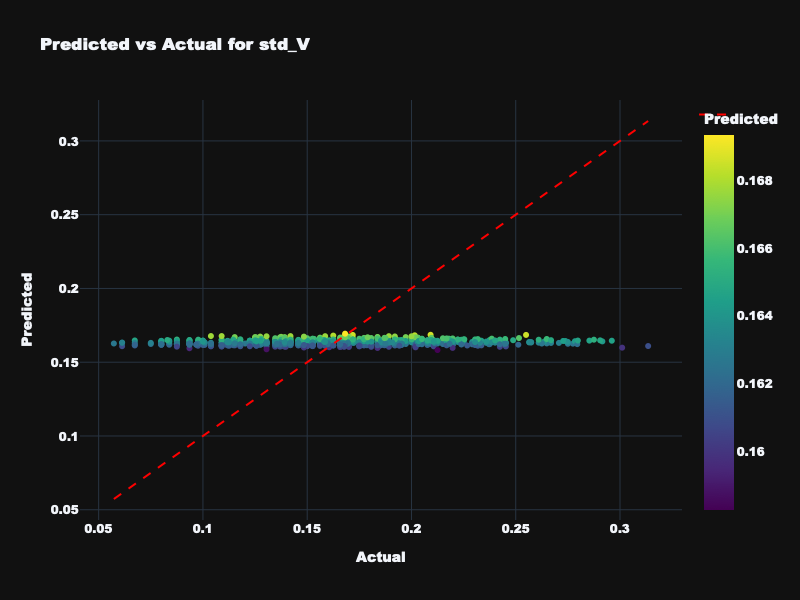
| std_V | 0.107 | 0.029 | -0.028 | Unpredictable — valence variance not captured by features |
Results: Dynamic Feature Dataset
Given the poor volatility prediction from static features, I tested whether dynamic temporal statistics (computed from time-varying acoustic properties) would better capture emotional variance.
| Target | Test R² | Best Alpha | Best L1 Ratio |
|---|---|---|---|
| mean_A | 0.657 | 0.001 | 0.1 |
| mean_V | 0.506 | 0.001 | 0.1 |
| std_A | 0.211 | 0.001 | 0.9 |
| std_V | -0.009 | 0.01 | 0.7 |
Hypothesis Outcome: Not Supported
Dynamic features produced similar results to static features, confirming that acoustic structure alone cannot reliably predict emotional volatility, particularly for valence.
Visualization: Static Feature Results
Predicted vs. actual emotion values for static acoustic features across all four targets.
Visualization: Dynamic Feature Results
Predicted vs. actual emotion values for dynamic temporal features across all four targets.
Key Findings & Implications
1. Acoustic Determinism vs. Listener Factors
While acoustic features excellently predict mean arousal (R² = 0.707) and moderately predict mean valence (R² = 0.493), they fail to explain variance in emotional responses. This suggests emotional volatility arises from listener-specific factors—personal history, context, mood, cultural background—rather than acoustic structure.
2. Distinct Feature Sets for Mean vs. Variance
The zero-intersection result in feature selection reveals that predicting average emotional response requires fundamentally different acoustic information than predicting variability. No single feature was important for all four prediction tasks.
3. Implications for Music Recommendation Systems
Truly personalized music recommendation systems must account for both acoustic properties and listener-specific contextual factors to understand the full spectrum of emotional response. Systems that only consider acoustic features will miss the interpersonal variance that makes music experiences uniquely personal.
This research demonstrates that some aspects of musical emotion are acoustically determined (mean responses), while others emerge from the interaction between music and individual listeners (emotional variance). Understanding this distinction is crucial for advancing both music emotion recognition and personalized listening experiences.
🎵 Future work will explore incorporating listener metadata, contextual information, and temporal dynamics to better model emotional volatility.